B树
B树是一种平衡的多叉树,通常我们说m阶的B树,它必须满足如下条件:
- 每个节点最多只有m个子节点。
- 每个非叶子节点(除了根)具有至少⌈ m/2⌉子节点。
- 如果根不是叶节点,则根至少有两个子节点。
- 具有_k_个子节点的非叶节点包含_k_ -1个键。
- 所有叶子都出现在同一水平,没有任何信息(高度一致)。
B树
什么是B树的阶
B树中一个节点的子节点数目的最大值,用m表示,假如最大值为4,则为4阶,如图
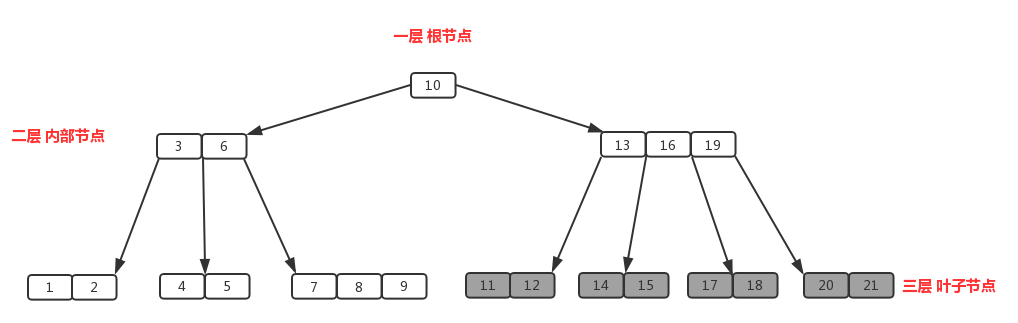
所有节点中,节点【13,16,19】拥有的子节点数目最多,四个子节点(灰色节点),所以可以定义上面的图片为4阶B树
B 树优势
二叉查找树这类型数据结构的问题在于,由于每个节点只能容纳一个数据,导致树的高度很高,逻辑上挨着的节点数据可能离得很远。
考虑在磁盘中存储数据的情况,与内存相比,读写磁盘有以下不同点:
- 读写磁盘的速度相比内存读写慢很多。
- 每次读写磁盘的单位要比读写内存的最小单位大很多。
由于读写磁盘的这个特点,因此对应的数据结构应该尽量的满足「局部性原理」:「当一个数据被用到时,其附近的数据也通常会马上被使用」,为了满足局部性原理, 所以应该将逻辑上相邻的数据在物理上也尽量存储在一起。这样才能减少读写磁盘的数量。
所以,对比起一个节点只能存储一个数据的 BST 类数据结构来,要求这种数据结构在形状上更「胖」、更加「扁平」,即:每个节点能容纳更多的数据, 这样就能降低树的高度,同时让逻辑上相邻的数据都能尽量存储在物理上也相邻的硬盘空间上,减少磁盘读写。
B+树
B+树是一种数据结构,是一个N叉排序树,每个节点通常有多个孩子,一棵B+树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点, 也可能是一个包含两个或两个以上孩子节点的节点。
B+树通常用于数据库和操作系统的文件系统中。NTFS、ReiserFS、NSS、XFS、JFS、ReFS和BFS等文件系统都在使用B+树作为元数据索引。B+树的特点是能够保持数据稳定有序, 其插入与修改拥有较稳定的对数时间复杂度。B+树元素自底向上插入。
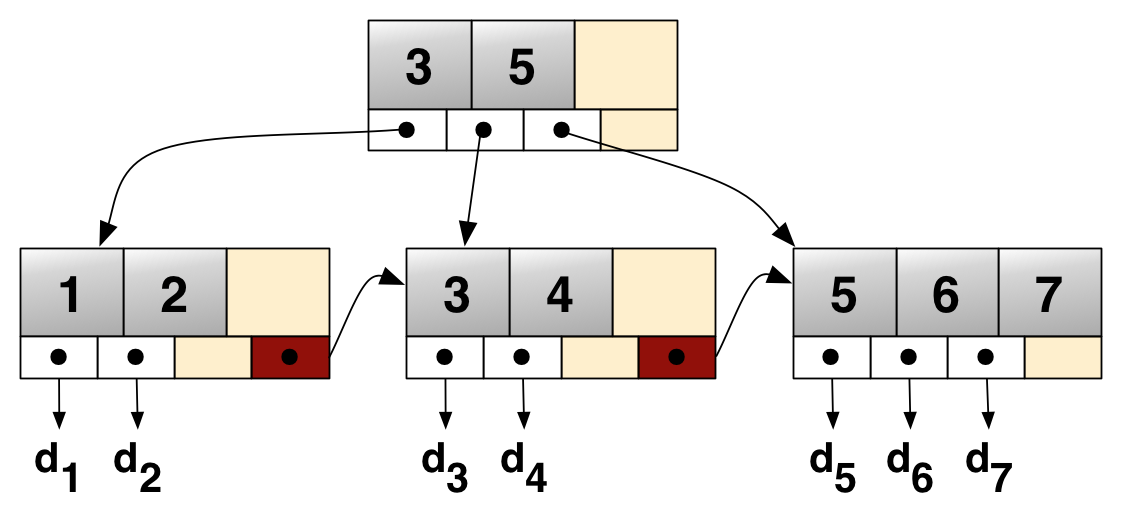
B+树的定义
B+树是应文件系统所需而出的一种B-树的变型树。一棵m阶的B+树和m阶的B-树的差异在于:
1) 有n棵子树的节点中含有n个关键字(即每个关键字对应一棵子树);
2) 所有叶子节点中包含了全部关键字的信息, 及指向含这些关键字记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接;
3) 所有的非终端节点可以看成是索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字
4) 除根节点外,其他所有节点中所含关键字的个数必须>=⌈m/2⌉(注意: B-树是除根以外的所有非终端节点至少有⌈m/2⌉棵子树)
MySQL采用B+树原因
MySQL等数据库普遍都采用B+树,而不是B-树。主要有如下原因:
1) B-树和B+树最重要的一个区别就是B+树只有叶子节点存放数据,其余节点用来索引。而B-树是每个索引节点都会有data域。这就决定了B+树更适合用来存储外部数据。也就是所谓的磁盘数据。
2) 从MySQL InnoDB的角度来看,B+树是用来充当索引的,一般来说索引非常大,尤其是关系型数据库这种数据量大的索引能达到亿级别,所以为了减少内存的占用,索引也会存储在磁盘上。
3) B+树的磁盘读写代价更低。B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B-树更小。如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
4) B+树的查询效率更加稳定。由于非终节点并不是最终指向文件内容的节点,而只是叶子节点中关键字的索引。所以任何关键字的查找必须走一条从根节点到叶子节点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
5) B+树所有的Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串起来。这样遍历叶子节点就能获得全部数据,这样就能进行区间访问了。