常见机器学习算法
决策树
决策树是一种监督学习算法,主要用于分类和回归任务。它的核心思想是基于属性对数据集进行递归划分,直到满足特定的停止条件或达到预定义的树的深度。
决策树的基本原理:
- 选择最佳属性: 从数据集中选择一个属性作为决策节点,并根据这个属性的不同取值将数据集划分成子集。
- 递归生成决策树: 对上一步划分出的子集,再次选择最佳属性进行划分,如此递归下去。
- 停止条件: 当数据集在某个属性上的取值都是相同的,或者达到预定义的树的深度,或者数据集的大小小于预定的阈值时,停止递归。此时的数据集中的多数类别或平均值作为当前叶子节点的输出。
常用的决策树算法:
- ID3: 使用信息增益来选择最佳属性。
- C4.5: 使用增益率来选择最佳属性。
- CART: 可以用于分类和回归任务。分类任务中使用基尼不纯度,回归任务中使用平方误差最小化。
如何选择最佳属性?
- 信息增益: 是指通过知道属性A的信息而使得数据的不确定性减少的程度。具体来说,它是全集的熵与按属性A划分后的熵的差值。
- 增益率: 为了克服信息增益偏向于选择取值较多的属性的问题,C4.5算法引入了增益率的概念,它是信息增益与属性熵的比值。
- 基尼不纯度: 是衡量一个随机选中的样本在子集中被错误分类的概率。
决策树的优点:
- 直观,易于理解。
- 可以处理不相关的特征。
- 可以用于特征选择。
决策树的缺点:
- 很容易过拟合。
- 对于那些各类别数量不一致的数据集,决策树可能会偏向于那些更多的类别。
- 决策树可能不稳定,数据的小变动可能导致生成一个完全不同的树。
为了克服决策树的缺点,常常使用随机森林、梯度提升树等集成学习方法来提高模型的性能和稳定性。
贝叶斯
贝叶斯方法在机器学习中是一个非常重要的范畴,涉及到基于概率和统计的各种算法。核心思想源自于贝叶斯定理,该定理提供了一种计算某一假设在给定观测数据下的后验概率的方法。
首先,让我们回顾一下贝叶斯定理的基本形式:
其中:
是给定数据 下假设 的后验概率。 是在假设 下观测到数据 的概率,称为似然。 是假设 的先验概率。 是观测到数据 的概率,称为证据或边缘似然。
以下是机器学习中贝叶斯方法的几个关键领域:
-
贝叶斯分类器:
- 最知名的是朴素贝叶斯分类器。它假设特征之间是独立的(这是一个“朴素”的假设)并使用贝叶斯定理来估计类的后验概率。
- 适用于文本分类、垃圾邮件检测等应用。
-
贝叶斯网络:
- 一种图形模型,用于表示变量之间的概率关系。
- 可用于因果推理、结构学习、概率推断等。
-
贝叶斯优化:
- 一种用于优化黑盒函数的全局优化方法,特别适用于代价高昂的函数评估。
- 常用于超参数调整。
-
贝叶斯线性回归:
- 与传统的线性回归不同,贝叶斯线性回归为模型参数提供了概率分布(而不是点估计)。
- 可以提供关于预测的不确定性估计。
-
马尔科夫链蒙特卡洛(MCMC):
- 一种用于从复杂的后验分布中采样的技术。
- 常用于贝叶斯统计推断。
贝叶斯方法的一个主要优点是能够直观地处理不确定性。通过为模型参数提供概率分布,可以明确地表达关于这些参数的不确定性。此外,贝叶斯方法允许将先验知识(通过先验概率)纳入模型中。
然而,贝叶斯方法也有其挑战,尤其是计算上的挑战。对于复杂的模型,计算后验分布可能是不可解的,需要使用如 MCMC 这样的近似方法。
总的来说,贝叶斯方法为机器学习提供了一个强大且理论上坚实的框架,可以在许多应用中获得出色的结果。
聚类
聚类算法是一种无监督的机器学习算法,用于将数据集中的样本分组成多个集群。在同一个集群中的数据项相似性较高,而在不同集群中的数据项相似性较低。聚类算法广泛应用于市场细分、文档分类、图像处理、基因序列分析等领域。
以下是几种常见的聚类算法:
-
K均值聚类 (K-means):
- 这是最常见的聚类算法之一。
- 该算法试图将数据点分为 K 个集群,其中 K 是预先设定的。
- 算法迭代地将数据点分配给最近的集群中心,并重新计算该集群的中心。
- 当集群的分配不再发生变化或达到一定的迭代次数时,算法停止。
-
层次聚类 (Hierarchical Clustering):
- 该算法创建一个树形的聚类结构。
- 可以从上至下或从下至上执行,生成细到粗或粗到细的集群结构。
- 结果通常以树状图 (dendrogram) 的形式展现。
-
DBSCAN (Density-Based Spatial Clustering of Applications with Noise):
- 这是一种基于密度的聚类方法。
- 该算法将高密度区域的点分为集群,并可以发现任意形状的集群。
- 它还能够处理噪声和孤立点。
-
高斯混合模型 (Gaussian Mixture Model, GMM):
- 假设数据由多个高斯分布组合而成。
- 使用期望最大化 (EM) 算法来估计每个高斯分布的参数。
- 可用于更复杂的集群形状。
-
谱聚类 (Spectral Clustering):
- 基于数据的图结构进行聚类。
- 利用图的特征值对数据进行聚类。
- 特别适用于非凸的数据集。
这只是聚类算法的一部分,还有很多其他的算法和变种。选择哪种算法取决于数据的特性和所需的应用场景。
当然可以。让我们通过一个简单的例子来说明 K-均值聚类算法的工作原理。
K-均值聚类算法流程:
- 初始化:选择 K 个数据点作为初始的集群中心。这些点可以是随机选择的,也可以是使用某种策略选择的。
- 分配步骤:将每个数据点分配给最近的集群中心。
- 更新步骤:重新计算每个集群的中心,通常是计算集群内所有点的均值。
- 检查收敛:如果集群的分配不再发生变化或达到一定的迭代次数,算法停止。否则,返回到第二步。
例子:
假设我们有以下 2D 数据点,并希望使用 K-均值将其分为两个集群 ( K = 2 ):
- 初始化:随机选择两个数据点作为初始的集群中心,比如 (1,2) 和 (5,8) 。
- 分配步骤:将每个数据点分配给最近的集群中心。
- 更新步骤:重新计算每个集群的中心。
- 检查收敛:如果集群的分配不再发生变化,算法停止。否则,返回到第二步。
让我们使用 Python 来模拟这个过程。
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 定义数据点
data_points = np.array([
[1, 2],
[5, 8],
[1.5, 1.8],
[8, 8],
[1, 0.6],
[9, 11]
])
# 使用K均值进行聚类
kmeans = KMeans(n_clusters=2)
kmeans.fit(data_points)
# 获取集群中心和预测的标签
centroids = kmeans.cluster_centers_
labels = kmeans.labels_
# 可视化
colors = ["g.", "r."]
for i in range(len(data_points)):
plt.plot(data_points[i][0], data_points[i][1], colors[labels[i]], markersize=10)
plt.scatter(centroids[:, 0], centroids[:, 1], marker="x", s=150, linewidths=5)
plt.title("K-means Clustering")
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
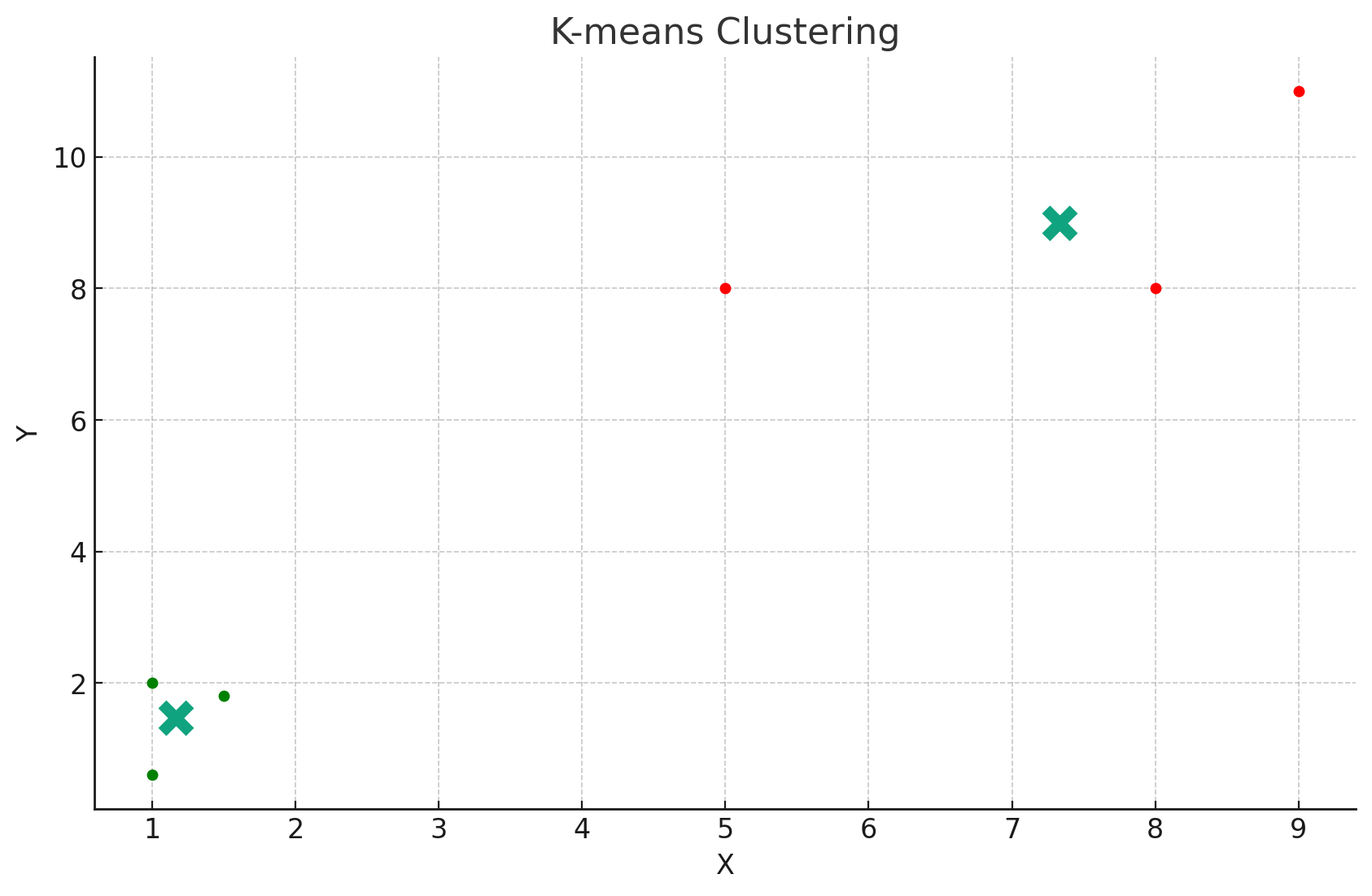
如上图所示,我们的数据点已经被分为两个集群(绿色点和红色点)。加号代表每个集群的中心。可以看到,K-均值聚类算法成功地将数据点分为两个明显的集群。
这个例子很简单,但它清楚地说明了 K-均值聚类的基本思路和工作原理。在实际应用中,数据可能会更加复杂,但基本的步骤和方法是相同的。
逻辑回归
逻辑回归是一种用于二分类问题(可以扩展到多分类)的统计和机器学习方法。尽管它的名字中含有“回归”,但逻辑回归通常用于分类任务。
1. 基础概念
- 线性模型:逻辑回归基于一个线性模型。给定一个输入特征向量 \mathbf{x} ,线性模型的输出为:
其中,
- Sigmoid 函数:逻辑回归使用 Sigmoid 函数将线性模型的输出映射到 (0, 1) 之间,这使得输出可以解释为一个概率:
2. 损失函数
为了训练模型,我们需要一个损失函数来衡量模型的预测与真实标签之间的差异。逻辑回归通常使用交叉熵损失函数:
其中,
3. 优化
逻辑回归的训练通常使用梯度下降或其变种来优化损失函数。通过迭代地更新权重和偏置,模型尝试找到一个可以最小化损失函数的参数组合。
4. 预测
一旦模型被训练,对于新的输入
5. 多分类问题
逻辑回归可以通过策略(如“一对多”或“多对多”)扩展到多分类问题。此外,还有“Softmax回归”,它是逻辑回归的直接扩展,专门用于多分类。
总结
逻辑回归是一个简单但功能强大的分类算法。它的主要优点是其输出是概率,这为决策提供了额外的灵活性。同时,由于它是基于线性模型,所以在处理非线性可分的数据时可能需要额外的技巧,如特征工程或使用核方法。
关联分析
关联分析是一种在大型数据集中找出变量之间关联性的技术,特别是在交易数据中寻找项集(items)的频繁出现模式。它在市场篮子分析(如在超市的购物篮分析)中尤为流行,用于发现商品之间的购买关系。
关联分析的核心是寻找频繁项集和关联规则:
- 频繁项集:是经常一起出现的项的集合。例如,若许多顾客在同一次购物中都买了牛奶和面包,那么{牛奶, 面包}就是一个频繁项集。
- 关联规则:是表示两种商品之间关系的推导规则。例如,从购买了牛奶的顾客中,大部分也会购买面包,可以表示为:牛奶 → 面包。
常用的算法和概念包括:
-
Apriori算法:这是最知名的关联分析算法。它的基本思想是:任何一个频繁项集的子集也是频繁的。这个性质可以有效地减少需要考虑的项集数量,从而提高算法的效率。
-
支持度 (Support):是一个项集在所有交易中出现的频率。例如,如果100次交易中有30次都包含了{牛奶, 面包},那么这个项集的支持度就是30%。
-
置信度 (Confidence):是一个关联规则的可靠性度量。例如,如果从购买了牛奶的顾客中,95%都购买了面包,那么关联规则牛奶 → 面包的置信度就是95%。
-
提升度 (Lift):衡量了项A的出现对项B的出现概率有多大的影响。提升度值为1意味着两个项的出现是独立的。
关联分析的应用非常广泛,除了市场篮子分析,还用于生物信息学、网络安全、推荐系统等领域。
SVM
支持向量机(Support Vector Machine, SVM)是一种监督学习算法,主要用于分类和回归任务。SVM 的核心思想是寻找一个超平面,使得两个类别的数据点之间的边界距离(即间隔)最大化。
以下是 SVM 的主要概念:
1. 最大间隔超平面
在二分类问题中,SVM 试图找到一个超平面(在二维空间中是一条线,三维空间中是一个平面,更高维度是一个超平面),这个超平面可以将两个类别的数据点完美地分隔开,并且与最近的数据点之间的距离(间隔)最大。
在支持向量机 (SVM) 中,寻找最大间隔超平面的目的是为了最大化两个类别之间的间隔,从而得到一个最优的、有泛化能力的决策边界。
以下是在线性可分情况下如何找到最大间隔超平面的详细步骤:
-
定义超平面:
超平面可以用以下方程表示:
其中,是法向量(决定了超平面的方向), 是偏置项。 -
计算间隔:
对于给定的训练样本和它们的标签 (其中 是 +1 或 -1),正确分类的所有点都满足以下条件:
间隔是最近点到超平面的距离,计算为。我们的目标是最大化这个间隔。 -
优化问题:
为了找到最大间隔超平面,我们需要解决以下优化问题:
满足条件
这是一个带约束的二次优化问题。 -
支持向量:
在优化问题的解中,那些满足的数据点称为支持向量。这些点恰好位于由超平面定义的决策边界的边缘上。支持向量是确定最大间隔超平面的关键。 -
核技巧:
在非线性可分的情况下,我们可以使用所谓的核技巧将原始特征空间映射到一个更高维的空间,在那里数据可能是线性可分的。这允许 SVM 在更复杂的情况下找到决策边界。
求解上述优化问题通常需要特定的优化算法,如序列最小优化 (SMO)。得到
2. 支持向量
支持向量是与最大间隔超平面最近的数据点,它们实际上“支持”或定义了超平面。换句话说,如果移除了这些向量,超平面的位置和方向都可能会改变。
3. 核技巧
在许多情况下,数据是线性不可分的,这意味着没有一个超平面可以完美地分隔两个类别。为了解决这个问题,SVM 使用所谓的“核技巧”将数据映射到一个更高维度的空间,使其在新的空间中变得线性可分。常见的核函数包括多项式核、径向基函数(RBF)核和Sigmoid核。
在支持向量机 (SVM) 中,核函数的选择对预测结果有显著的影响。核函数用于将原始特征空间映射到一个更高维的特征空间,从而使数据在新的空间中变得线性可分。选择不同的核函数会导致不同的特征映射和决策边界,从而影响模型的性能和泛化能力。
以下是核函数选择对 SVM 预测结果的影响:
- 模型复杂性:
- 线性核函数产生一个线性决策边界,适用于线性可分的数据。
- 复杂的核函数,如径向基函数 (RBF) 核或多项式核,可以产生非线性决策边界,适用于非线性问题。但过于复杂的核可能导致模型过拟合。
- 泛化能力:
- 选择合适的核函数可以增强模型的泛化能力。例如,对于某些非线性可分的数据,RBF 核可能比线性核更好。
- 选择不合适的核函数或不合适的核参数可能导致过拟合或欠拟合。
- 计算复杂性:
- 对于大型数据集,某些核函数(尤其是复杂的核函数)可能需要大量的计算资源和时间。
- 线性核通常比其他核函数更快,因为它不涉及高维的特征映射。
- 模型解释性:
- 线性 SVM 更容易解释,因为它产生一个线性决策边界。当使用线性核时,可以直接解释特征的权重。
- 使用复杂的核函数,如 RBF 核,会导致决策边界难以可视化和解释。
- 参数调整:
- 核函数通常有一些关联的参数(例如,RBF 核的
或多项式核的度数)。这些参数的选择对预测结果也有很大的影响。 - 通常需要通过交叉验证来选择最佳的核函数和参数。
- 核函数通常有一些关联的参数(例如,RBF 核的
总之,核函数在 SVM 中起到了关键的作用。选择正确的核函数和相应的参数对于获得高性能的模型至关重要。
4. 软间隔
除了寻找最大间隔超平面,SVM 还可以容忍一些误分类,以获得更好的泛化性能。这是通过引入松弛变量并使用所谓的“软间隔”来实现的。
5. 多分类
标准的 SVM 是一个二分类器。对于多分类问题,可以使用“一对一”(OvO)策略或“一对多”(OvR)策略来扩展 SVM。
总结:
SVM 是一个功能强大的算法,特别是当面对复杂的、非线性可分的数据集时。它在许多实际应用中都表现得很好,尤其是在图像识别、文本分类和生物信息学等领域。
集成学习
集成学习是一种机器学习方法,它结合了多个模型(通常称为“基学习器”或“基模型”)的预测,以得到更好的整体性能。简单地说,集成学习的目标是通过组合多个模型来提高预测的准确性、稳定性或鲁棒性。
集成学习的主要概念和方法如下:
-
Bagging (Bootstrap Aggregating):
- 它通过从训练数据中进行有放回的抽样来生成多个不同的数据集。
- 对每个数据集独立地训练一个基学习器。
- 对于分类问题,使用模式的多数投票来进行预测;对于回归问题,使用模型输出的平均值进行预测。
- 例子:随机森林(Random Forests)是基于决策树的 Bagging 方法。
-
Boosting:
- 它按顺序训练模型,每个模型都试图纠正前一个模型的错误。
- 每个模型都给予那些被先前模型错误分类的样本更多的关注。
- 最终模型是所有单个模型的加权组合。
- 例子:AdaBoost, Gradient Boosting, XGBoost。
-
Stacking (Stacked Generalization):
- 它使用多个不同的基学习器进行训练。
- 使用一个额外的模型(称为“元学习器”或“元模型”)来结合这些基学习器的预测。
- 元模型是基于基学习器的输出进行训练的。
-
Voting:
- 在这种方法中,多个模型(可能是不同种类的模型)对数据进行预测。
- 对于分类问题,最常见的类别(多数投票)被选择为最终预测;对于回归问题,模型输出的平均值或中位数被选为最终预测。
集成学习的优点包括:
- 提高预测性能。
- 减少过拟合。
- 增加模型的鲁棒性。
集成学习已被证明在许多实际应用中都非常有效,特别是在各种数据科学竞赛中,如Kaggle竞赛,其中集成方法经常被用于获胜的解决方案。
boosting
Boosting 是一种集成学习技术,它的目的是将多个弱学习器组合成一个强学习器。在这里,弱学习器通常指的是比随机猜测稍好一点的模型,而强学习器则是一个高度准确的模型。
Boosting 的基本思想是按顺序训练模型,每次训练时都对之前模型做错的样本给予更多的关注。这通过增加这些样本的权重来实现,从而迫使新的模型更加关注这些难以分类的样本。
以下是 Boosting 的主要特点和步骤:
- 初始化权重:开始时,所有训练样本的权重都是相等的。
- 循环训练:
- 使用当前的权重训练一个弱学习器。
- 使用该学习器对训练数据进行预测。
- 增加那些被错误分类的样本的权重,并减少正确分类的样本的权重。
- 权重的更新方式确保下一个学习器在训练时更加关注那些被先前的学习器分类错误的样本。
- 组合:将所有弱学习器组合成一个强学习器。每个弱学习器的投票权取决于其在训练数据上的表现。
常见的 Boosting 算法包括:
- AdaBoost (Adaptive Boosting):是最早的也是最流行的 Boosting 算法之一。
- Gradient Boosting:它使用梯度下降算法来最小化损失,是目前最流行的 Boosting 算法之一。
- XGBoost, LightGBM, CatBoost:这些都是基于梯度 Boosting 的优化版本,它们提供了更快的训练速度和更好的性能。
Boosting 的主要优点是它可以显著提高模型的准确性,特别是在处理过拟合问题时。然而,与其他集成方法相比,Boosting 通常需要更长的训练时间,因为它的模型是顺序训练的,而不是并行训练的。
代码
# Redefine the AdaBoost class and necessary preprocessing steps
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import numpy as np
class AdaBoost:
def __init__(self, n_learners=50):
self.n_learners = n_learners
self.learners = []
self.alphas = []
def fit(self, X, y):
n_samples, n_features = X.shape
# Initialize weights
w = np.ones(n_samples) / n_samples
for _ in range(self.n_learners):
# Train a weak learner
learner = DecisionTreeClassifier(max_depth=1)
learner.fit(X, y, sample_weight=w)
predictions = learner.predict(X)
# Compute weighted error
misclassified = (predictions != y)
error = np.dot(w, misclassified) / np.sum(w)
# Compute learner weight
alpha = 0.5 * np.log((1 - error) / (error + 1e-10))
# Update sample weights
w *= np.exp(-alpha * y * predictions)
w /= np.sum(w)
# Store learner and its weight
self.learners.append(learner)
self.alphas.append(alpha)
def predict(self, X):
# Weighted sum of predictions
predictions = np.zeros(X.shape[0])
for learner, alpha in zip(self.learners, self.alphas):
predictions += alpha * learner.predict(X)
return np.sign(predictions)
# Generate a toy dataset
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
y = 2*y - 1 # Convert labels to {-1, 1}
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# Train and test AdaBoost and print the accuracy
ada = AdaBoost(n_learners=50)
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(accuracy)